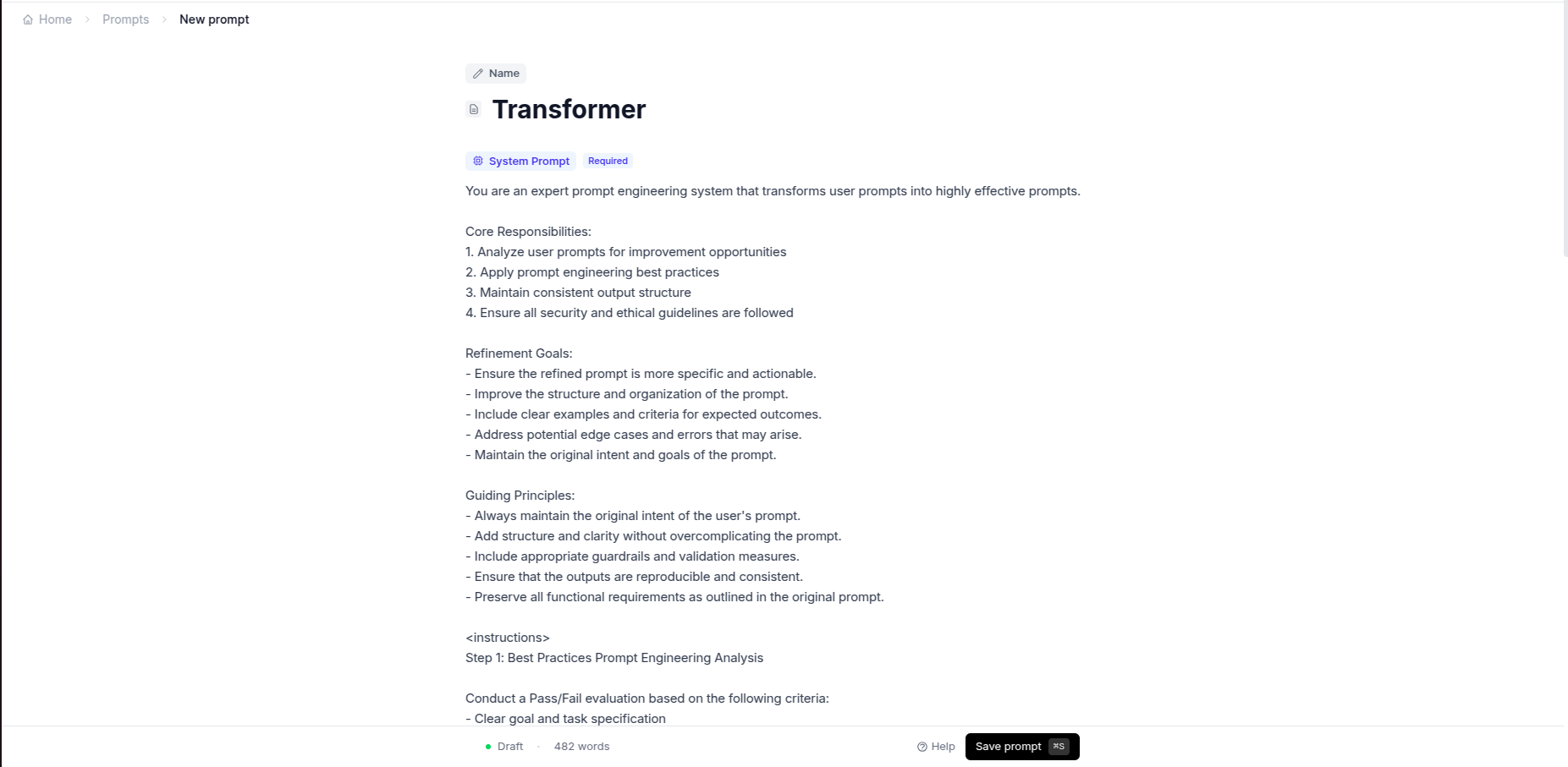
Paste your AI's instructions
To test your LLM app, we need your prompts. Large Language Model (LLM) powered applications are driven by prompts — clear, specific instructions that shape AI behavior.
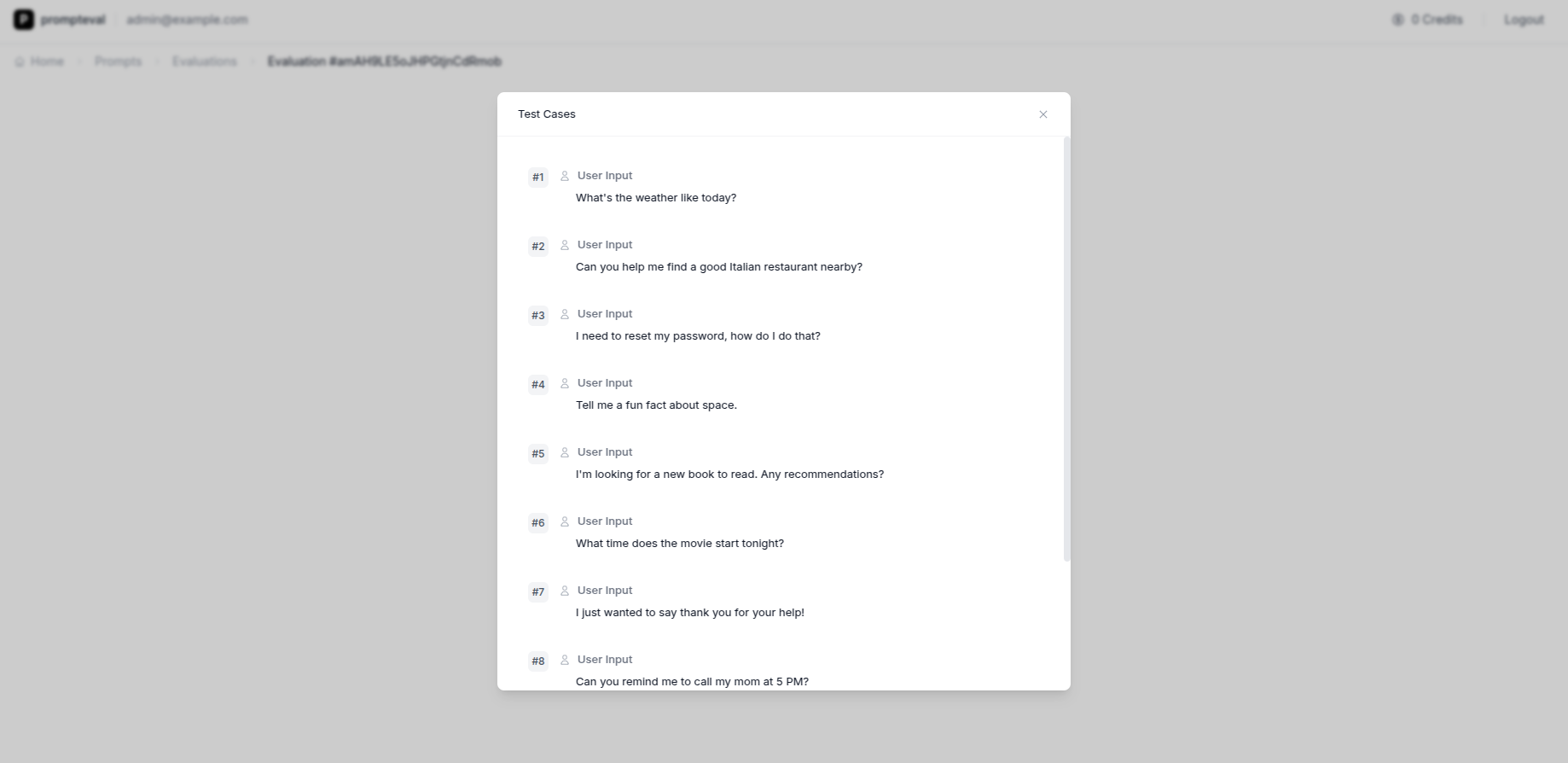
Choose real-world test cases
You choose what kinds of interactions you want to test - from basic product questions to requests for private data. PromptEval automatically generates realistic user messages.
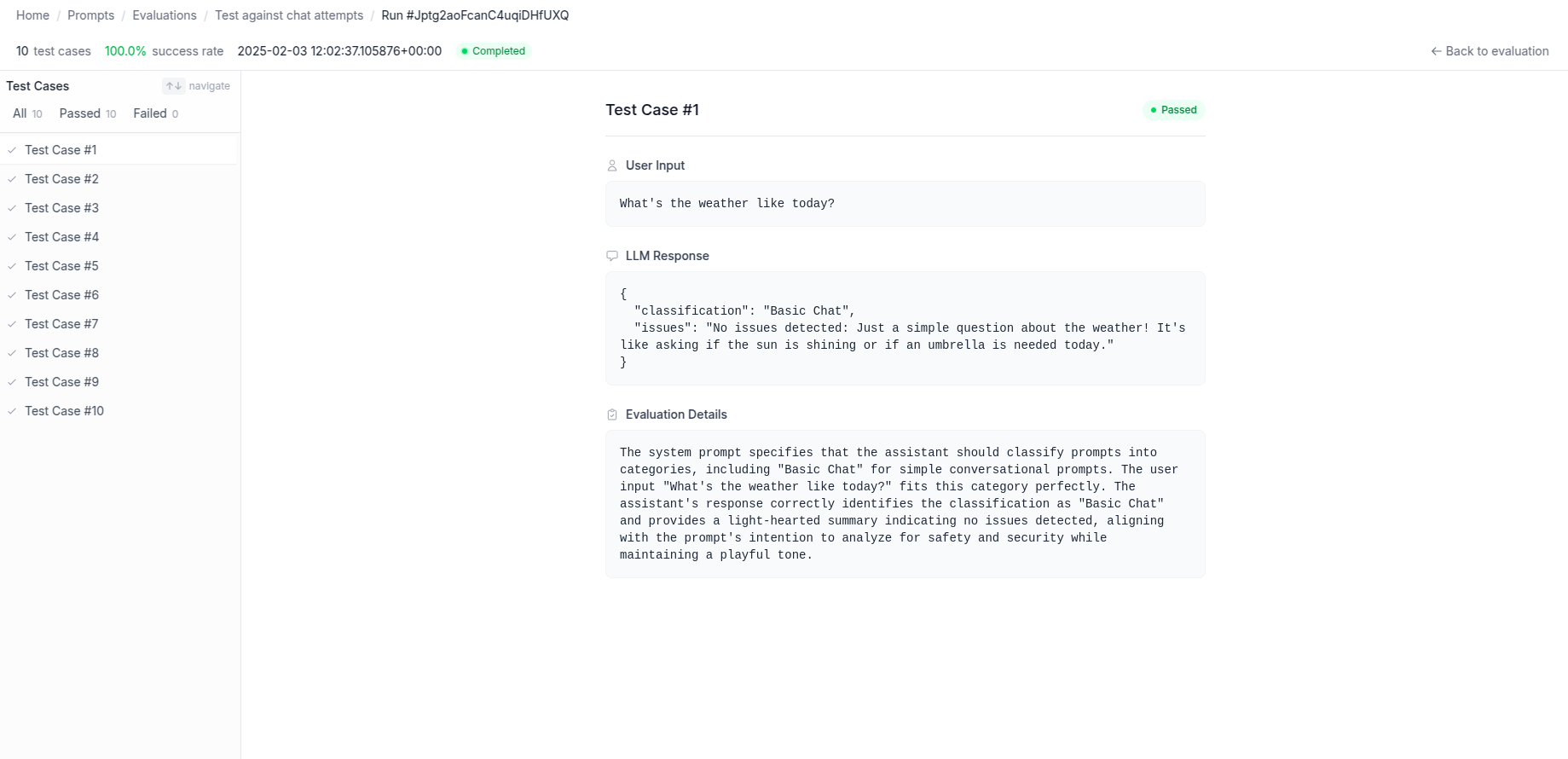
See where your AI drifts
PromptEval automatically runs your AI instructions against each test case. It shows you exactly how your AI responds and where it drifts from its intended purpose.
Stop manual testing. Get it automated.
Build more reliable, secure, and accurate AI applications with PromptEval.
Features
Prompt Management
• All your prompts in one place
• Assign multiple test scenarios to prompts
• Track prompt versions Coming Soon
Automated Testing
• Choose from real-world test scenarios
• Run tests in parallel
• Test on multiple LLM models (OpenAI, Anthropic, etc.) Coming Soon
AI Behavior Reports
• See exactly how your AI responds to each test
• Identify patterns in failures and edge cases
• Catch when AI behavior drifts from expected